英語が苦手なので普段は和英辞書WebサイトのWeblioを愛用しています。
Weblioの辞書をターミナルから検索や表示ができると色々便利かもと思い、プログラミングの練習も兼ねて作成してみました。
経緯
主に使うソフトを2つに絞るとalt+tabのショートカットキーで瞬時にソフトを切り替えられるので、普段はターミナルとEmacsを常用しています。
基本的にはターミナルとEmacsで完結できる場合が多いんですが、ブラウザで和英辞書を引くこともしばしばあります。
そうすると、ショートカットでソフトの切り替えをする際に面倒なので、ターミナルから辞書を引けると便利かなと思い試しに作ってみました。
使用例
$PATHの通ったディレクトリにコピーして、コマンドと検索ワードを入力します。
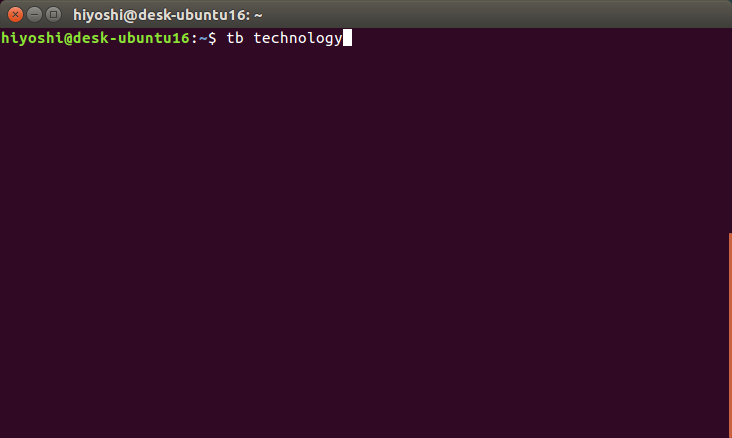
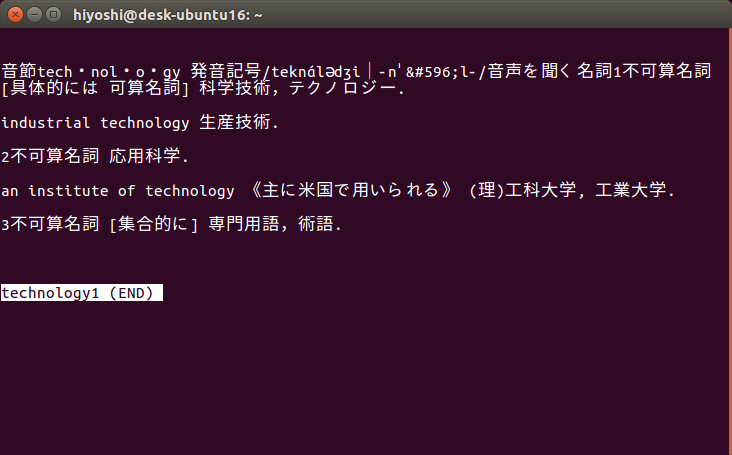
検索結果がターミナル上で表示されます。
ソースコード
短いのでソースコードも載せてみます。
#! /bin/sh wget -q http://ejje.weblio.jp/content/$1 c_terblio $1 less $1"1" rm $1 $1"1"
#include <stdio.h>
#include <string.h>
// skip to KEYSTRING
#define KEYSTRING "<h2 class=midashigo"
int main(int argc, char *argv[])
{
FILE *fp_i, *fp_o;
char fname[128] = {0};
char str[10000];
char c;
int newline_cnt;
int len;
if (argc != 2) {
fprintf(stderr, "%s\n", "usage: tb en_word");
}
strncpy(fname, argv[1], strlen(argv[1]));
len = strlen(argv[1]);
fname[len] = '1';
fname[len+1] = '\0';
if ((fp_i = fopen(argv[1], "r")) == NULL) {
perror("fopen");
return 1;
}
if ((fp_o = fopen(fname, "w")) == NULL) {
perror("fopen");
return 1;
}
// until body tag is read
while (strncmp(fgets(str, sizeof(str), fp_i), KEYSTRING, strlen(KEYSTRING)) != 0) {
}
// when body tag was not found
if (strncmp(str, KEYSTRING, strlen(KEYSTRING)) != 0) {
fprintf(stderr, "%s\n", "body tag was not found");
return 1;
}
// output the extracted data
newline_cnt = 0;
while (((c = fgetc(fp_i)) != EOF) && (newline_cnt < 3)) {
if (c == '<') {
while (c != '>') {
c = fgetc(fp_i);
}
continue;
}
fputc(c, fp_o);
if (c == '\n') {
newline_cnt++;
}
if (c == '.') {
fputc('\n', fp_o);
fputc('\n', fp_o);
}
}
return 0;
}
プログラム内でHTTP通信してhtmlファイルを取得するコードを書いたことがないので、wgetでHTMLファイルを取得して、Cのプログラムでタグの削除と表示の調整をしています。
表示に関してですが、和英英和辞書サイトのHTMLが想定したソースコードよりも煩雑だったので、上手く調整できていません。
HTTP通信の書き方を覚えたら、書き換えてみようと思います。
GitHub: hiyoshisaizo/terblio: Terminal Dictionary
終わりに
この記事を書いている最中に気づきましたが、テキストブラウザのコマンドと和英英和辞書サイトのURLをエイリアスしておけば同じようなことができますね。
両方試してみて使いやすい方を使っていこうと思います。

Linux/Ubuntuのターミナル上で和英辞書を表示する「terblio」